Dakota Access Pipeline is no longer an unfamiliar name. The controversy over the pipeline comes from two opposing views. On the one hand, people are of afraid of (water) pollution. On the contrary, the corporation responsible for the pipeline says it’s safe. So the question is clear: Is the pipeline really safe?
It’s hard to answer this for a not operational pipeline, but we can look at pipeline incidents data to answer if pipelines are safe. Fortunately, the Pipeline and Hazardous Materials Safety (PHMS) Administration provides data on every single pipeline accidents from 1986 to now. The dataset is rich with a lot of raw data showing all kinds of details about the accidents.
The analysis of the pipeline data is not unprecedented. The New York Times in 2014, created an interactive map of environmental incidents in North Dakota from 2006-2014. Back in 2015, High Country News wrote a piece on crude oil spills after an incident in Santa Barbara costing more than $62M at the time. Also after an incident in North Dakota, Inside Energy analyzed wastewater spills in North Dakota. All these articles emphasize that the spills are not as rare as one might think.
This post is my take on the pipeline incidents. I’m interested in answering these specific questions:
- How common are spills?
- What is their spatial and temporal distributions?
- What is their scale regarding volume and cost?
- What are the main causes of spills?
- What places have a higher risk?
There are tons of other questions to ask, but these are basic questions to understand the problem better. Hopefully, similar studies are done for policy making.
Dataset and technical details
I am doing the analysis in Python using its standard libraries:
numpypandasmatplotlib
I also use plotly, but only for plotting points on the US map. I have customized matplotlib style using the recommendations of this post.
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
%matplotlib inline
plt.style.use('ggplot')
plt.rcParams['font.family'] = 'sans-serif'
plt.rcParams['font.serif'] = 'Helvetica Neue'
plt.rcParams['font.monospace'] = 'Helvetica Neue'
plt.rcParams['font.size'] = 10
plt.rcParams['axes.labelsize'] = 10
plt.rcParams['axes.labelweight'] = 'bold'
plt.rcParams['axes.titlesize'] = 12
plt.rcParams['xtick.labelsize'] = 10
plt.rcParams['ytick.labelsize'] = 10
plt.rcParams['legend.fontsize'] = 10
plt.rcParams['figure.titlesize'] = 12
You can download the dataset from PHMS website with xlsx format. The dataset is broken into different time periods. Here I only focus on the data from 2010-2016 (filename is hl2010toPresent, converted to CSV format). Although, many incidents in 2016 are not reported yet. This data contains massive details of each incident (having 255 columns for each record shows this!). I only select a few columns and rename them to be more descriptive:
- Year
- Location (longitude and latitude)
- Commodity type
- The released volume (in barrels)
- State
- Release type
- Whether water was contaminated
- Total cost (in 1984 dollars)
- Cause
I make a few changes in the dataset to make it more approachable:
- The cost comes in 1984 dollar. According to this website, \$1 in 1984 is equal to \$2.3 in 2016.
- The released volume is in barrels, so I convert it to gallons which I have a better sense of (1 barrel = 42 US gallons).
- The commodity names are long, so I make them shorter.
usefulcols=["LOCAL_DATETIME","IYEAR","LOCATION_LATITUDE","LOCATION_LONGITUDE",
"COMMODITY_RELEASED_TYPE","UNINTENTIONAL_RELEASE_BBLS","ONSHORE_STATE_ABBREVIATION",
"RELEASE_TYPE","WATER_CONTAM_IND","TOTAL_COST_IN84","CAUSE"]
dataset = pd.read_csv("./hl2010toPresent.csv", usecols = usefulcols)
dataset.columns = ["time", "year", "lat", "long", "commodity", "volume","state", "release type", "water","cost","cause"]
dataset['commodity'].unique()
dataset['commodity'].replace(
{'REFINED AND/OR PETROLEUM PRODUCT (NON-HVL) WHICH IS A LIQUID AT AMBIENT CONDITIONS':'REFINED LIQUIDS',
'CO2 (CARBON DIOXIDE)': 'CARBON DIOXIDE',
'HVL OR OTHER FLAMMABLE OR TOXIC FLUID WHICH IS A GAS AT AMBIENT CONDITIONS':'FLAMMABLE GASES',
'BIOFUEL / ALTERNATIVE FUEL(INCLUDING ETHANOL BLENDS)':'BIOFUEL'
}
, inplace=True)
# convert to gallons
dataset['volume'] = 42 * (dataset['volume'].astype(int))
# convert to 2016 dollars
dataset['cost'] = 2.3 * dataset['cost']
# save the cleaned dataset in a new file
dataset.to_csv('./hl2010toPresent_cleaned.csv',index=False)
dataset.head(5)
| time | year | lat | long | commodity | volume | state | release type | water | cost | cause | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2/16/10 7:42 | 2010 | 41.94352 | -88.23353 | REFINED LIQUIDS | 0 | IL | LEAK | NO | 38379.865371 | EQUIPMENT FAILURE |
| 1 | 3/1/10 11:50 | 2010 | 37.10847 | -100.80037 | CARBON DIOXIDE | 84 | KS | OTHER | NO | 4414.659264 | OTHER INCIDENT CAUSE |
| 2 | 2/22/10 10:38 | 2010 | 32.22471 | -101.40440 | FLAMMABLE GASES | 42 | TX | LEAK | NO | 33782.834143 | CORROSION FAILURE |
| 3 | 2/19/10 6:50 | 2010 | 40.60860 | -74.23990 | REFINED LIQUIDS | 0 | NJ | LEAK | NO | 21507.314365 | EQUIPMENT FAILURE |
| 4 | 2/21/10 12:45 | 2010 | 31.13284 | -101.18974 | CRUDE OIL | 378 | TX | LEAK | NO | 21991.543373 | CORROSION FAILURE |
Spread of spills
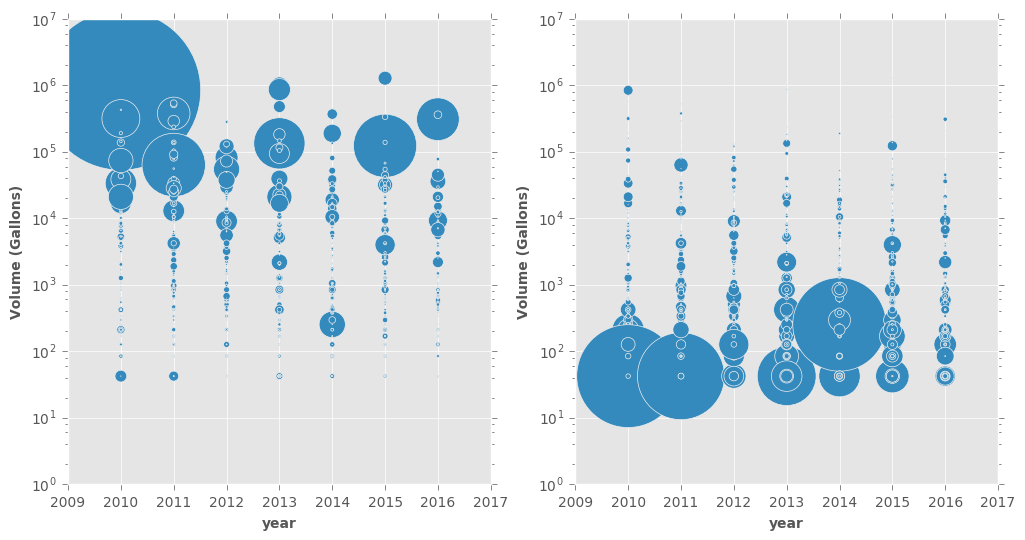
The first plot shows the volume of the released commodities for all incidents in each year. Both plots are exactly the same, except the marker size is representing two different things. On the left plot, the size shows the cost of the spill. Unsurprisingly, the most costly incidents are those with a high volume usually $>10^4$.
The right panel, on the other hand, offers an alternative and interesting view (and it looks like they are a bunch of earrings!). The size of each point is proportional to the cost of the spill divided by the release volume. This reveals a very interesting trend: The cost per volume is more for small spills! I don’t know exactly why but my guess is the actions need to be taken are partly independent of the spill volume (this is up for debate, of course).
fig, axes = plt.subplots(nrows=1, ncols=2,figsize=(12,6))
dataset.plot.scatter(x="year", y="volume",s=dataset.cost/80000,ax=axes[0])
dataset.plot.scatter(x="year", y="volume",s=0.04*dataset.cost/dataset.volume,ax=axes[1])
for ax in axes:
ax.get_xaxis().get_major_formatter().set_useOffset(False)
ax.set_yscale('log')
ax.set_xlim([2009,2017])
ax.set_ylim([10**0,10**7])
ax.set_ylabel('Volume (Gallons)')
plt.show()
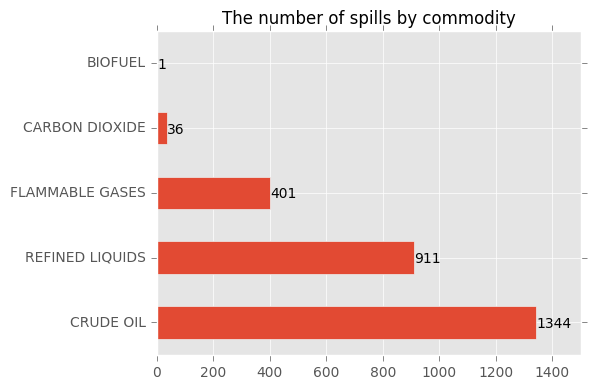
Based on the commodity, the crude oil is the leading released commodity. Among 2693 incidents (roughly 1.5 incidents a day) reported from 2010 to October 2016, 1344 incidents involve releasing crude oil followed by refined fluid by 911 incidents. Together they make up ~$\%84$ of the incidents.
ax = dataset["commodity"].value_counts(sort=True).plot.barh()
ax.set_title("The number of spills by commodity")
for p in ax.patches:
ax.annotate('{:.0f}'.format(p.get_width()), (1.1*p.get_x()+p.get_width(), p.get_y()+p.get_height()/3 ))
ax.set_xlim(0,1500)
plt.tight_layout()
plt.show()
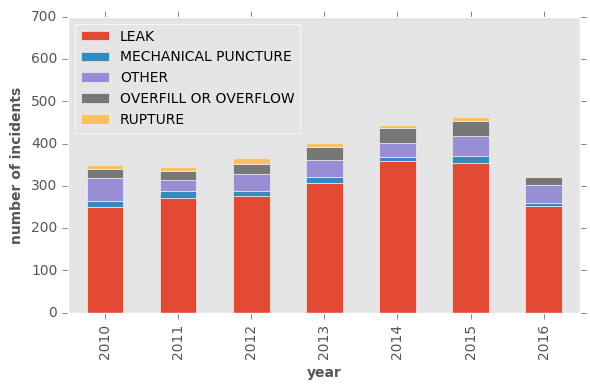
It is worrying that number of the incidents has been constantly growing. Let’s look at the data by year and the reason of spill. Obviously leak is the leading cause and unfortunately constantly number of the leaks is increasing. I see no reason that this trend stops at this year. Other causes have more or less the same frequency over these years.
release_year = pd.crosstab(dataset['year'],dataset['release type'])
ax = release_year.plot(kind='bar', stacked=True, grid=False)
ax.set_ylabel("number of incidents")
ax.set_xlabel("year")
ax.legend(loc = 'upper left')
ax.set_ylim(0,700)
plt.tight_layout()
plt.show()
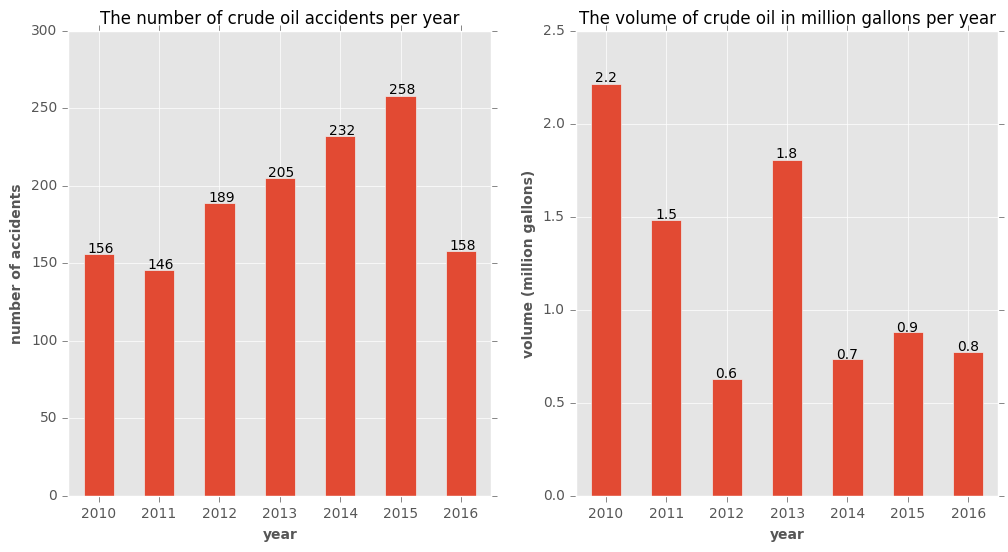
From here on, I will focus on incidents involving crude oil only. The number of such incidents has constantly increased with the exception of 2011. But the released volume follows no such pattern. Also, as dataset clearly mentions, part of the released oil can be recovered but it is not reported in the dataset. In 1344 incidents of crude oil, more than 8.5 million gallons are released.
data = dataset[dataset["commodity"]=="CRUDE OIL"]
data.head()
| time | year | lat | long | commodity | volume | state | release type | water | cost | cause | date | ctime | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 4 | 2/21/10 12:45 | 2010 | 31.13284 | -101.18974 | CRUDE OIL | 378 | TX | LEAK | NO | 21991.543373 | CORROSION FAILURE | 2010-02-21 | 2/21/10 12:45 |
| 8 | 2/20/10 6:30 | 2010 | 32.47850 | -94.86790 | CRUDE OIL | 336 | TX | OVERFILL OR OVERFLOW | YES | 117614.823872 | EQUIPMENT FAILURE | 2010-02-20 | 2/20/10 6:30 |
| 10 | 3/1/10 9:16 | 2010 | 47.68857 | -95.41732 | CRUDE OIL | 126 | MN | OVERFILL OR OVERFLOW | NO | 23997.634976 | INCORRECT OPERATION | 2010-03-01 | 3/1/10 9:16 |
| 13 | 3/1/10 8:10 | 2010 | 32.48325 | -94.83034 | CRUDE OIL | 8316 | TX | RUPTURE | NO | 20146.442193 | CORROSION FAILURE | 2010-03-01 | 3/1/10 8:10 |
| 16 | 1/25/10 11:07 | 2010 | 29.47000 | -90.25444 | CRUDE OIL | 8484 | LA | OVERFILL OR OVERFLOW | YES | 838911.034004 | EQUIPMENT FAILURE | 2010-01-25 | 1/25/10 11:07 |
fig, axes = plt.subplots(nrows=1, ncols=2,figsize=(12,6))
data["year"].value_counts(sort=False).plot(kind='bar',rot=0,ax=axes[0])
axes[0].set_title("The number of crude oil accidents per year")
axes[0].set_ylabel("number of accidents")
axes[0].set_xlabel("year")
for p in axes[0].patches:
# write number on the bars
axes[0].annotate('{:.0f}'.format(p.get_height()), (p.get_x() + p.get_width()/8, p.get_height() * 1.005))
(data.groupby(['year'])['volume'].sum()/(10**6)).plot(kind='bar',rot=0,ax=axes[1])
axes[1].set_title("The volume of crude oil in million gallons per year")
axes[1].set_ylabel("volume (million gallons)")
axes[1].set_xlabel("year")
for p in axes[1].patches:
axes[1].annotate('{:.1f}'.format(p.get_height()), (p.get_x() + p.get_width()/8, p.get_height() * 1.005))
plt.show()
Which states are dealing with the incidents?
Texas by far has the most spills, followed by Oklahoma, California, and Wyoming. In fact, Texas and Oklahoma deal with more than %51 of the incidents. This is not unexpected as according to Railroad Commission of Texas:
Texas has the largest pipeline infrastructure in the nation, with more than 439,771 miles of pipeline representing about 1⁄6 of the total pipeline mileage of the entire United States.
ax=data["state"].value_counts(sort=True).plot(kind='bar')
ax.set_title("The number of crude oil accidents in different states")
ax.set_ylabel("number of accidents")
ax.set_xlabel("state")
plt.show()
# share of the first two states from the incidents
data["state"].value_counts(sort=True,normalize=True)[0:2].sum()
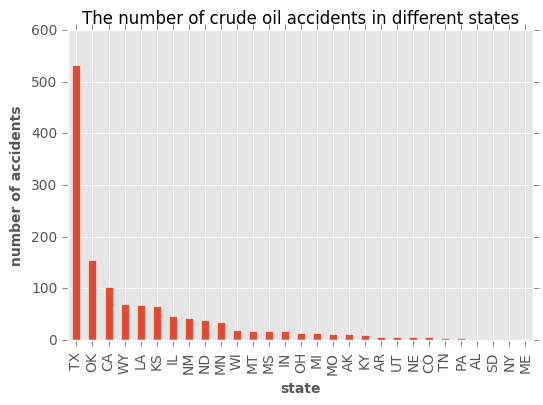
0.51190476190476186
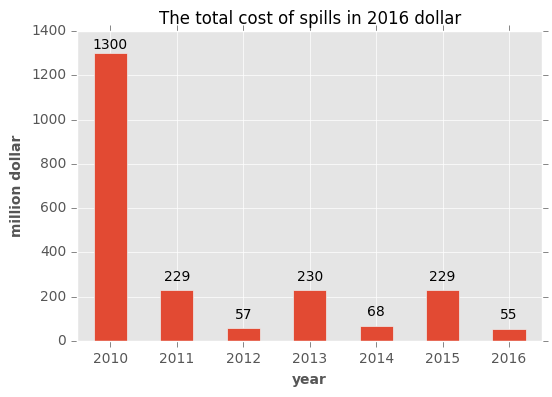
What is total money spent?
Another factor in a pipeline incident is the cost of each incident. Shown in 2016 dollar, look at the alternating pattern in the cost. This is probably because cleaning and fixing the issue takes a long time (maybe about a year?). Also, the companies are supposed to report the data at the end of fixing and cleaning process, so some incidents are not reported completely. The total reported cost so far has been $2.16 billion since 2010.
ax = (data.groupby(['year'])['cost'].sum()/10**6).plot(kind='bar',rot=0)
ax.set_title("The total cost of spills in 2016 dollar")
ax.set_ylabel("million dollar")
ax.set_xlabel("year")
for p in ax.patches:
ax.annotate('{:.0f}'.format(p.get_height()), (p.get_x()+ p.get_width()/2, p.get_height() * 0.98),
ha='center', va='center', xytext=(0, 10), textcoords='offset points')
plt.show()
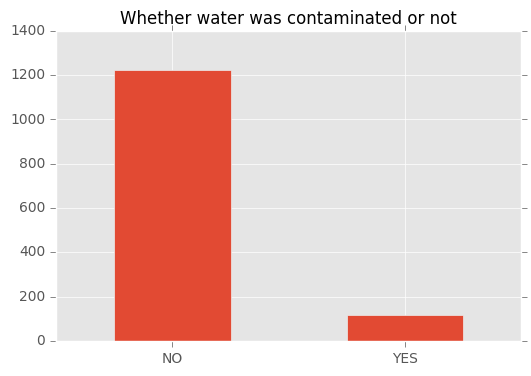
Was water contaminated?
Maybe the most concerning aspect of spills is whether they pollute the water. Fortunately, this is often not the case (in %91 of cases). Although, we don’t know if those spills happen close to the water or not. Maybe, we have been lucky that pipelines mostly are not crossing close to the water resources.
data['water'].value_counts().plot.bar(title="Whether water was contaminated or not",rot=0)
plt.show()
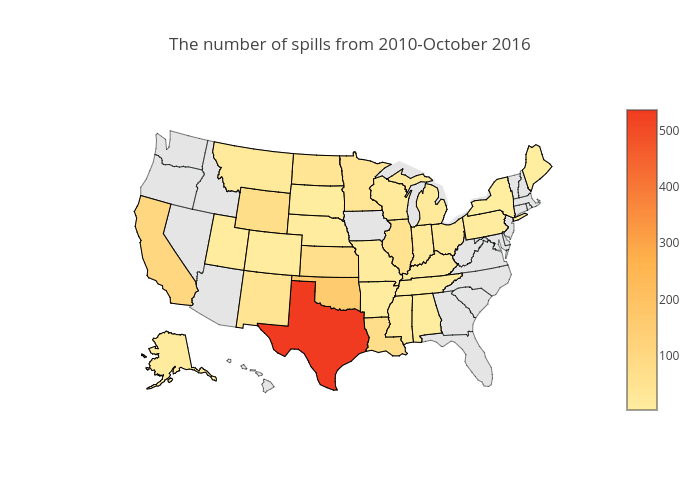
Geographic distributions
The color intensity represents the number of spills in each states. The color palettes on the US map is from colorbrewer2. As it was mentioned, Texas is by far the worst state in terms of number of incididents.
from plotly.offline import download_plotlyjs, init_notebook_mode, plot, iplot
from IPython.display import Image
init_notebook_mode(connected=True)
import plotly.plotly as py
df = pd.DataFrame(data["state"].value_counts(sort=True).reset_index())
df.columns = ["code","counts"]
datax = [ dict(
type='choropleth',
autocolorscale = False,
colorscale=[[0, 'rgb(255,237,160)'],[0.5, 'rgb(254,178,76)'],[1, 'rgb(240,59,32)']],
locations = df["code"],
z = df["counts"],
locationmode = 'USA-states',
marker = dict(line = dict (color = 'rgb(0,0,0)',width = 1,) ),
colorbar = dict(title = ""),
) ]
layout = dict(
title = 'The number of spills from 2010-October 2016',
geo = dict(
scope='usa',
projection=dict( type='albers usa' ),
showland = True,
landcolor = "rgb(229, 229, 229)",
subunitcolor = "rgb(0,5,5)",
countrycolor = "rgb(0,50,5)",
countrywidth = 0.5,
subunitwidth = 0.5
),
)
fig = dict( data=datax, layout=layout )
#iplot( fig, filename='./d3-cloropleth-map',) #image='png'
#py.image.save_as(fig,'./incident_states.png')
Image('./incident_states.png')
Incidents on map
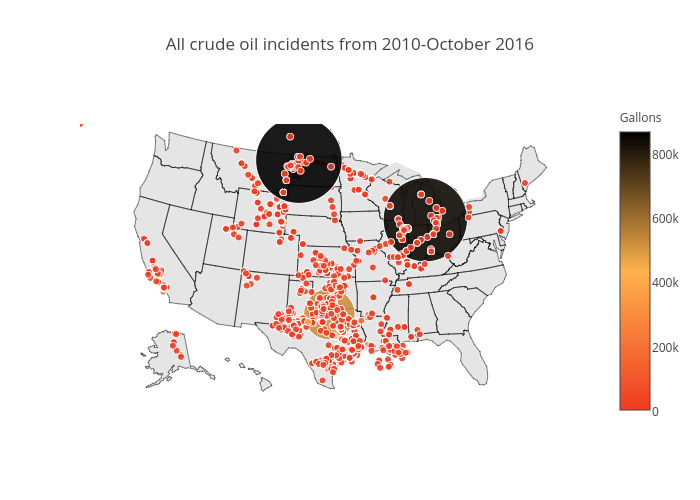
Finally, maybe the most informative plot is the spatial distribution of all incidents. The map shows that spills really happen wherever there is a pipeline. Possibly connecting points will show exactly where pipelines are placed. The color of points is proportional to the released volume. The two large black points are two accidents in North Dakota (July 2013, 865000 gallons, \$20 million) and Michigan (July 2010, 843000 gallons, \$1 billion).
datax = [ dict(
type = 'scattergeo',
locationmode = 'USA-states',
lon = data['long'],
lat = data['lat'],
text = data['cost'].astype(str),
mode = 'markers',
hoverinfo = 'lon+lat+location',
marker = dict(
size = 9,
symbol = 'circle',
line = dict(width=1,color='rgba(10, 10, 1)'),
opacity = 0.9,
reversescale = False,
autocolorscale = False,
colorscale=[[0, 'rgb(255,237,160)'],[0.5, 'rgb(254,178,76)'],[1, 'rgb(240,59,32)']],
cmin = 0,
color = data['volume'],
cmax = data['volume'].max(),
colorbar=dict(title="Gallons"),
))]
layout = dict(
title = 'All crude oil incidents from 2010-October 2016',
geo = dict(
scope='usa',
projection=dict( type='albers usa' ),
showland = True,
landcolor = "rgb(229, 229, 229)",
subunitcolor = "rgb(0,5,5)",
countrycolor = "rgb(0,50,5)",
countrywidth = 0.5,
subunitwidth = 0.5
),
)
fig = dict( data=datax, layout=layout )
#iplot( fig, filename='d3-airports' )
#py.image.save_as(fig,'./incident_ditribution.png')
Image('./incident_ditribution.png')
Conclusion & future ideas
During the period 2010 to October 2016, more than 8.5 million gallons of crude oil is spilled. The total cost of these spills is well over 2 billion dollars. In one of the worst cases, 843444 gallons was released in Michigan, resulting in a massive 1 billion cost in 2016 dollars and water contamination. In 2016 alone, more than 54 million dollars is the cost of releasing 800000 gallons of crude oil. Although, it is claimed that most incidents happen within the facilities not in the public land. Although, confirming this needs further analysis.
As Christofer Jones, historian of energy at ASU points out: “While it’s true that improved technology and regulation have reduced spills significantly—much like flying today is far safer than in the early years of commercial aviation—the fact remains that there exists no such thing as a spill-proof pipeline. Recognizing this historical reality is crucial to crafting future policy.”
Whether this is currently a real priority is another question. At the time of writing, there are 188 federal and 340 state inspectors to inspect “2.7 million miles of pipelines, 148 liquefied natural gas plants, and 7,574 hazardous liquid breakout tanks.”
This quick analysis shows different aspects of the pipeline incidents but many aspects of this dataset is unexplored. Some that I can think of are:
- The number of casualties,
- Whether the pipeline is underground or on ground ,
- possible seasonal/temporal patterns in incidents (one might guess winters are the worst seasons!),
- Whether the spill happened close to the well or far from the pipeline. This is important as some pipelines cross lands close to farming areas and cities.
- How long was the response time?
- What are the most vulnerable areas? Is the vulnerability related to their age?
- How does cost depend on the commodity, volume and cost?
- Categorizing spills based on the volume and cost because many spills have really small volumes.
I’ll be grateful to hear your ideas, comments, and suggestions!
This post is written in Jupyter notebook and is available with the required dataset as a github repository.